
ℹ️NOTE: Kaskada is now an open source project! Read the announcement blog.
The incredible hype surrounding machine learning has precipitated a vast ecosystem of tools designed to support data scientists in the model development lifecycle. However, this has also made selecting the right suite of tools more challenging, as there are now so many different options to choose from. When evaluating a particular product, the key is to assess if, and how, it will enable you to perform your job more reliably, quickly, and impactfully. Towards that end, what follows are 6 factors to consider that you can use to better understand how Kaskada will impact your existing workflow.
1. Development Velocity and Throughput
In an ideal world, data scientists would have as much time as they’d like to test, tweak, and recalibrate their models. Unfortunately, models have a shelf life, businesses need to make an impact, and as more models are deployed more need to be maintained—we call this the data-dependency debt shown in the figure below. In addition, the huge hype around ML means business leaders have correspondingly high expectations of it. You as a data scientist need to be able to demonstrate value by rapidly iterating on feature definitions and models in order to produce results.
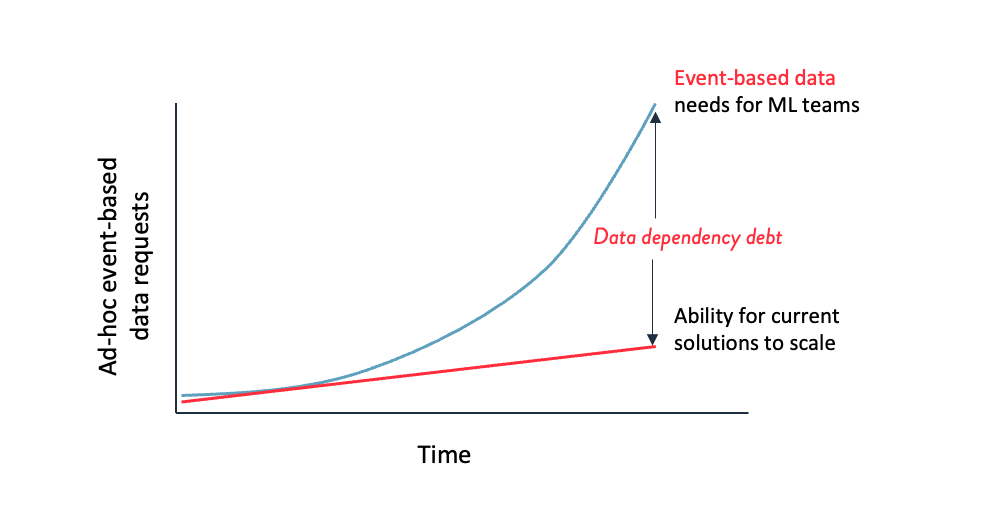
Data-dependency debt:
As more models are deployed more need to be maintained, and other solutions can’t scale to meet the demand for the event-based data needs for ML teams.
One of the biggest time sinks for data scientists is the feature engineering and selection process. Especially problematic in this regard is creating new features using time series, event-based, or streaming data in which changing a feature definition can mean having to rerun a computation across the entire historical dataset, or settling for proxy features with suboptimal model performance.
Feature engines such as Kaskada offer a rich time-traveling toolset to enable instant iteration on your feature definitions as training examples are observed via the ability to interact with slices of datasets. By slicing a vast dataset and preserving its statistical properties, experimental features run significantly faster, thereby enabling you to experiment on a subset of your entities. This frees you up to focus on asking the right questions, building the best features, and testing your hypothesis instead of waiting for backfill jobs or settling for proxy datasets captured at suboptimal points in time.
In addition, maintaining models via retraining and validation on new data becomes simpler, increasing your throughput. Generating a labeled training dataset with new data is a matter of running a query, and, if it turns out that your features are no longer predictive, finding new ones is significantly faster. Plus, testing new models needed at a different prediction time, from existing feature definitions, is a matter of adjusting a single line of code and rerunning the query.
2. Runtime Efficiency
While a lot of tools can seem great on smaller datasets or on pre-aggregated data, the way they’re implemented under the hood can sometimes be subpar in terms of runtime efficiency for event-based data, leading to drastic inefficiencies that slow down your workflow or don’t enable you to operate at the scale you’d like. Feature engines such as Kaskada have a different computational model that is temporal and always incremental. Kaskada is time and entity aware, reorganizes data, and efficiently caches as needed in various stages. Kaskada can be deployed into your cloud with configurable resource allocation allowing you to scale your feature engine performance to meet your feature computation needs.
Generating training datasets is only half the job of a feature engine. Runtime efficiency can be even more important in a production environment, where the features for many more entities need to be computed and maintained. Kaskada is a declarative feature engine, and customers can use our Amazon AMI to deploy one or more instances of Kaskada’s feature engine inside of their own infrastructure in the region where their data is located. The ability to deploy multiple feature engines gives you the ability to trade off costs and efficiency as needed. Now your CI/CD automation processes can deploy new features and feature engines quickly, without costly code rewrites.
3. Compatibility and Maintainability
A new tool won’t do you much good if it doesn’t integrate well with upstream and downstream components, such as ML modeling libraries. The best tools will drop into your existing data science toolset and work alongside most, if not all the tools you’re already using—while adding additional capabilities or increasing your productivity.
Kaskada is available as a package in Python, the most popular language for data science, and it can query databases via a query language called FENL, which is even easier to use than SQL. You can connect once to all your structured event-based data — enabling access to the source of truth powering the downstream pre-aggregated data sources that you’re used to working with. This data contains additional information necessary to explore behavior and context. All this while allowing you to iterate in your existing workflow using the python client library, our APIs, or other integrations to explore and create new time-based features.
Queries return dataframes and parquet files for easy integration with your visualization, experiment tracking, model training, AutoML, and validation libraries. Kaskada also enables reproducibility and audibility via data-token-ids to compute incremental changes, audit previous results and track as metadata with experiments, models and predictions.
4. ML Model Performance
Of course, a primary consideration in a data scientist’s workflow is the performance of the model. This is also where you as a data scientist demonstrate value to the organization. Without a high-performing model that has a direct, positive impact on business KPIs, the data scientist’s job is irrelevant.
There are several ways to measure model performance, from common accuracy scores to train-test data set measures in the lab. Precision, recall, F1 scores, and uncertainty and confidence are all factors to consider for a model’s performance. But these scores only tell you if the model is performing as intended when you actually take these measurements across inclusivity and fairness variables that you’re looking.
Part of the difficulty in training a model to improve KPIs is that the connection between the two is often fuzzy and hard to discern. It can be difficult to understand and interpret how incremental changes to the model affect the downstream KPIs. However, this problem can often be ameliorated by building explainable models with clear feature definitions.
When working with event-based and streaming data, these feature definitions are often more complicated to express and compute than those involved in static models, making the discernment process even more challenging. Often these features are subject to drift and require bias handling using evaluation methods to spot erroneous predictions. They are also subject to frequent retraining and evaluation.
Feature engines such as Kaskada illuminate the relationship between features, model performance, and KPI improvements by transforming complicated event-based feature definitions into clear readable, expressions using logical operators, allowing data scientists to uncover the hidden relationships between models and business processes. In addition, Kaskada provides rapid development and training speed, shortening the time to bring a data science product to market. With Kaskada you can discover new, relevant features with 1000x more self-service iterations on train, test and evaluation data sets. Ultimately this leads to keeping your models performing better at a 26x faster pace.
5. Transparency
As alluded to before, part of a data scientist’s job lies in generating explanations for complex phenomena. In order to do this reliably, the data scientist has to first be able to understand how each of the tools in their toolchain operates and affects both data and models. Kaskada provides transparency in three complementary ways.
Transparency is first achieved through readability, and queries for behavioral ML are more concise to write in Kaskada. Compared to an existing survival analysis accelerator, Kaskada recently simplified the code from 63 pages down to 2. Since features in Kaskada can be fully described by a single, composable, and concise query they are also much easier to understand, debug and get right.
In addition, rewriting feature definitions from historical to real-time data systems is a common and frustrating source of bugs. Computing features using a feature engine eliminates common developer errors and simplifies code by sharing the same feature definition computed at the current time. This makes it easier to understand for anyone who needs to fiddle with the model, connect results to business processes, update feature definitions, or otherwise write code within the surrounding software system.
Second, Kaskada is a transparent tool in its own right. Data scientists can easily inspect the results of their queries on existing data by defining views, and they can watch as these views automatically update in response to incoming streaming data. In doing so, data scientists gain a better understanding of how their feature definitions apply to their datasets and are able to adjust the features and models accordingly.
Finally, for every query, historical or real-time, a data-token-id is returned for logging. This token provides a snapshot of the data, and combining it with the query allows for reproducing the state of the data and the resulting feature values to audit why a certain prediction was made and justify the decision of the model.
6. Support and Documentation
Even in the best of hands, tools will inevitably break or fail to operate in an expected way. It is in these times that the true strength (or weakness) of the organization backing a product is revealed. You’ll want a product that has robust, well-maintained documentation that explains all of the product’s features. You’ll also want access to solution accelerators where you can see how the tool is used to accomplish common tasks in existing applications.
Finally, you’ll want an organization you can turn to for personal support when debugging fails or when something breaks. Having access to technical members of the product’s development team who can get to the root of the problem is crucial. Kaskada provides documentation of all product features, demos and case studies, and enterprise support for issues that arise in development and production. It is also under active development by a team that is responsive to users’ issues and feature requests, both within an enterprise context and beyond.
Final Thoughts
Committing to an ML tool, particularly something as integral as a feature engine, is not a decision to be taken lightly. Because ML models are built on features, having features that are easily understandable, efficiently computed, scalable, and can accommodate event-based data is imperative for maximizing your efficiency as a data scientist and cementing your value to an organization. Being able to demonstrate value by connecting improvements in business results and KPIs to the models you implement is the key to being promoted and obtaining greater influence and reach within your organization. An excellent feature engine such as Kaskada will enable you to get more done, have an outsized impact in your role, and work to your peak potential.